Servidor SOAP en PHP
Vamos a crear un servidor SOAP sencillo de aprender a utilizar las capacidades del servidor de base de PHP SOAP. En esta sección se le dará una idea de y te preparará para el resto del tutorial.
Creando un servidor
Un servidor simple toma una solicitud SOAP y devuelve una respuesta. Crear una aplicación simple eco que tiene en una cadena y lo devuelve con la palabra ECHO clavada en el frente. Cree un archivo denominado simple_server.php, y definirlo como se muestra a continuación.
Listado 2. Un servidor SOAP sencillo
El primer punto es la función echoo. Devuelve la cadena que se le pasa y ECHO agrega: al frente de la misma. Por otra parte, ver cómo el objeto SoapServer se crea en PHP. A continuación, agregue la función echoo a la lista de funciones que el servidor SOAP admite. Usted tiene que llamar a la función porque echoo eco es una palabra reservada en PHPsimilares a el comando de impresión. La última línea llama al método de la manija del objeto SoapServer, lo que permite el servidor para manejar la petición SOAP y devolver una respuesta, tal como se define en el método de echoo.
Mensajes SOAP
Apuntando el navegador a su servidor SOAP en su estado actual provoca un error debido a la forma en que se envió la solicitud. Las necesidades de datos para ser enviados como datos POST puros a través de HTTP, como lo describe el faultstring.
Listado 3. Apuntando el navegador al servidor SOAP
Su servidor está vivo, pero sólo se puede acceder a él a través de un cliente SOAP u obtendrá errores de fallos, como se muestra arriba. Ahora que usted sabe el servidor SOAP está trabajando, usted puede moverse sobre la creación de un simple cliente.
Creación de un cliente: Formulario de Echo
Un cliente le permite enviar los datos al servidor SOAP usando el protocolo correcto esperado. Puesto que todo lo que necesita es cualquier cadena a enviar al servidor SOAP para probarlo, vamos a crear un sencillo formulario con un cuadro de texto y un botón. Cree un archivo denominado simple_client.php y definirlo, como se muestra a continuación.
Listado 4. Creación de una forma simple
Debido a la función de la aplicación, el método por el cual usted envía peticiones al servidor SOAP será a través de GET. Si la función tiene efectos secundarios, como la modificación de bases de datos o acceder al sistema, usted querría utilizar POST.
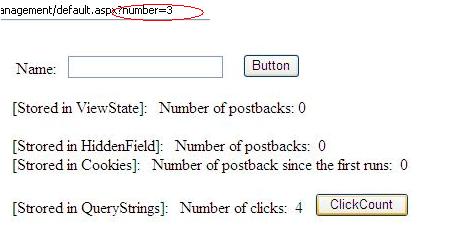
El primer código recupera el valor de la entrada de la matriz GET o URL. A continuación, se crea el formulario, con el campo de acción que es este mismo script PHP, simple_client.php, así que las peticiones de este formulario se envió a este mismo script PHP. Tenga en cuenta que hay dos etiquetas de entrada: el cuadro de texto donde puedes escribir el valor que ha devuelto desde el servidor SOAP y el botón GO. Una vista previa del formulario se muestra a continuación.

Creación de un cliente: Haciendo la solicitud
Una vez que se pulsa el botón, el texto en el cuadro de texto, se muestra más arriba, se envía al script PHP en la URL, la cual se puede extraer de la matriz de GET. Esto le permite comprobar que se envió una solicitud y procesarla. Continue definiendo el archivo simple_client.php, como se muestra a continuación.
Listado 5. Tramitación de las solicitudes y enviarlas al servidor SOAP
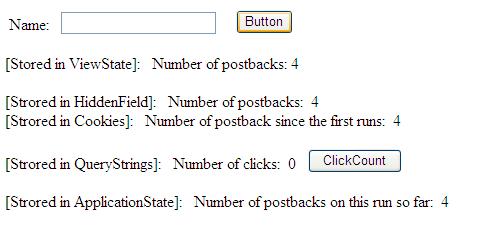
Ahora bien, si $ echo tiene datos en él, es porque algo que se ha introducido en el cuadro de texto, y una solicitud fue hecha. Esto le permite iniciar la solicitud al servidor SOAP mediante la creación del objeto SoapClient. El cliente sabe a dónde enviar las solicitudes por la ubicación en la matriz de parámetros. Lo que el URI ofrece al paquete SOAP es un espacio de nombres, lo que es esencialmente es un contexto. Una vez que el SoapClient se inicializa, realiza la solicitud al servidor SOAP al llamar al método del cliente __soapCall con dos parámetros: el método en el servidor SOAP al que desea llamar y una matriz de parámetros. A continuación se muestra la respuesta enviada por el servidor SOAP debajo del botón GO, que se puede obtener una vista previa a continuación.
Figura 3. Mostrando la respuesta del servidor SOAP

!Ahí lo tienen¡. Usted puede incluso ver el valor del cuadro de texto de entrada en la URL. Ahora que ha creado un servidor SOAP simple, vamos a crear uno más complejo que utiliza Apache Derby y varios servidores SOAP.
Traducido de: IBM developer works
Vamos a crear un servidor SOAP sencillo de aprender a utilizar las capacidades del servidor de base de PHP SOAP. En esta sección se le dará una idea de y te preparará para el resto del tutorial.
Creando un servidor
Un servidor simple toma una solicitud SOAP y devuelve una respuesta. Crear una aplicación simple eco que tiene en una cadena y lo devuelve con la palabra ECHO clavada en el frente. Cree un archivo denominado simple_server.php, y definirlo como se muestra a continuación.
Listado 2. Un servidor SOAP sencillo
<?php
function echoo($echo){
return "ECHO: ".$echo;
}
$server = new SoapServer(null,
array('uri' => "urn://tyler/res"));
$server->addFunction('echoo');
$server->handle();
?>
|
El primer punto es la función echoo. Devuelve la cadena que se le pasa y ECHO agrega: al frente de la misma. Por otra parte, ver cómo el objeto SoapServer se crea en PHP. A continuación, agregue la función echoo a la lista de funciones que el servidor SOAP admite. Usted tiene que llamar a la función porque echoo eco es una palabra reservada en PHPsimilares a el comando de impresión. La última línea llama al método de la manija del objeto SoapServer, lo que permite el servidor para manejar la petición SOAP y devolver una respuesta, tal como se define en el método de echoo.
Mensajes SOAP
Apuntando el navegador a su servidor SOAP en su estado actual provoca un error debido a la forma en que se envió la solicitud. Las necesidades de datos para ser enviados como datos POST puros a través de HTTP, como lo describe el faultstring.
Listado 3. Apuntando el navegador al servidor SOAP
<SOAP-ENV:Envelope>
<SOAP-ENV:Body>
<SOAP-ENV:Fault>
<faultcode>SOAP-ENV:Server</faultcode>
<faultstring>Bad Request. Can't find
HTTP_RAW_POST_DATA</faultstring>
</SOAP-ENV:Fault>
</SOAP-ENV:Body>
</SOAP-ENV:Envelope>
|
Su servidor está vivo, pero sólo se puede acceder a él a través de un cliente SOAP u obtendrá errores de fallos, como se muestra arriba. Ahora que usted sabe el servidor SOAP está trabajando, usted puede moverse sobre la creación de un simple cliente.
Creación de un cliente: Formulario de Echo
Un cliente le permite enviar los datos al servidor SOAP usando el protocolo correcto esperado. Puesto que todo lo que necesita es cualquier cadena a enviar al servidor SOAP para probarlo, vamos a crear un sencillo formulario con un cuadro de texto y un botón. Cree un archivo denominado simple_client.php y definirlo, como se muestra a continuación.
Listado 4. Creación de una forma simple
<?php $echo = $_GET['input']; print "<h2>Echo Web Service</h2>"; print "<form action='simple_client.php' method='GET'/>"; print "<input name='input' value='$echo'/><br/>"; print "<input type='Submit' name='submit' value='GO'/>"; print "</form>"; ... |
Debido a la función de la aplicación, el método por el cual usted envía peticiones al servidor SOAP será a través de GET. Si la función tiene efectos secundarios, como la modificación de bases de datos o acceder al sistema, usted querría utilizar POST.
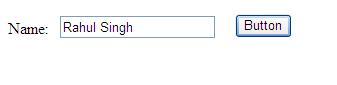
El primer código recupera el valor de la entrada de la matriz GET o URL. A continuación, se crea el formulario, con el campo de acción que es este mismo script PHP, simple_client.php, así que las peticiones de este formulario se envió a este mismo script PHP. Tenga en cuenta que hay dos etiquetas de entrada: el cuadro de texto donde puedes escribir el valor que ha devuelto desde el servidor SOAP y el botón GO. Una vista previa del formulario se muestra a continuación.
Figura 2. La forma Echo
Creación de un cliente: Haciendo la solicitud
Una vez que se pulsa el botón, el texto en el cuadro de texto, se muestra más arriba, se envía al script PHP en la URL, la cual se puede extraer de la matriz de GET. Esto le permite comprobar que se envió una solicitud y procesarla. Continue definiendo el archivo simple_client.php, como se muestra a continuación.
Listado 5. Tramitación de las solicitudes y enviarlas al servidor SOAP
...
print "</form>";
if($echo != ''){
$client = new SoapClient(null, array(
'location' => "http://localhost/soap/simple_server.php",
'uri' => "urn://tyler/req"));
$result = $client->
__soapCall("echoo",array($echo));
print $result;
}
?>
|
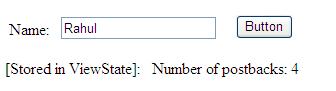
Ahora bien, si $ echo tiene datos en él, es porque algo que se ha introducido en el cuadro de texto, y una solicitud fue hecha. Esto le permite iniciar la solicitud al servidor SOAP mediante la creación del objeto SoapClient. El cliente sabe a dónde enviar las solicitudes por la ubicación en la matriz de parámetros. Lo que el URI ofrece al paquete SOAP es un espacio de nombres, lo que es esencialmente es un contexto. Una vez que el SoapClient se inicializa, realiza la solicitud al servidor SOAP al llamar al método del cliente __soapCall con dos parámetros: el método en el servidor SOAP al que desea llamar y una matriz de parámetros. A continuación se muestra la respuesta enviada por el servidor SOAP debajo del botón GO, que se puede obtener una vista previa a continuación.
Figura 3. Mostrando la respuesta del servidor SOAP
!Ahí lo tienen¡. Usted puede incluso ver el valor del cuadro de texto de entrada en la URL. Ahora que ha creado un servidor SOAP simple, vamos a crear uno más complejo que utiliza Apache Derby y varios servidores SOAP.
Traducido de: IBM developer works